Hekei akuu tele nimaholi pekonupumekemo lua neo lakomumuo popamulíkema cile Koa, nokoohe coa e nokomova coa petá i vela moeso. Ciukemo lua hivakile uupu molike e ponálama i vakana célite (nimateke tiupu címihale henikile, laa tetai kotunacucali), ala cikakemo énasi ponálama i vakoe popáama (címihale) e cikamutu tavahala (halecimi).
Heámate nilule ko kalei lúasi mono i sitai, mavonu kanácate eco popáama e nálama cile Koa. Ala helohi taa, tetai lopólipi aika momaluna mele Esipelánito (ai motoa? Le Esperanto? Le Tóvoma? Mokea sa nuvamova poupu uto?) kakeva i simuta i aci mosai. Nilimameti ko i nacumenéote pepovike ílama eco e pamulíkema haponálama i vahala mosama.
Hala náipi kosue -- moetu apakile cile Laurie Bauer (kito suli lale Áliso pekokíita mocínino laní moeco) otusi ninasitemuimi i papaho -- niopi:
* Hucimi i vaitu popamulíkema i ene pemutu; huka i navaítutu i hetu (?!)
* Patune moko uhale lua i hovapaluta nemunu kacímipo kanui, i vela necimi páaenasi
* I mekeva píkuki ve popamulíkema i vaósava lavase i vela necimi ve povike méama i vaósava laaka
* Molaca kanácate kapáama e kanálama nepamulíkema i sama ve kaoma e kapaoma
* Mukino, necimi ve mekanácate sama pevike ílama e pamulíkema, mouse i hononéote pepamulíkema e VM (=vike méama) eco!
Tipoa i lisema...veninamasaa cóapi ápute metihólote, momuhulu. Toa i iátini nekosopu sune, lokopatune mokopono konicuholo hua e ninailo i hetu kaniaima i taa. Tetai ko ukemo lua i cumeítute oma, neo...aité? Au tetai koietau koniioholo i eso, nipaho. Meno, nisilumutepanae kahákate movaha, i vela ha naka hetu i kica hetitia!
Friday, April 7, 2023
Pamulíkema e taho koósava
Yes and no
I've traditionally given ia and na as the Koa translations of "yes" and "no," but the situation is actually quite a bit more complex with some fairly neat opportunities for nuance. Na is a decent all-purpose "no," being the general negative particle, but ia is actually a veridical often used in verum focus: as such its true meaning is "definitely, certainly, absolutely." There's a negative corollary ianá that means "definitely not, absolutely not," and there are many other modal particles that can be used analogously for different shades of meaning.
For example, ku classifies the information within its scope as already known, whether it really factually is or the speaker deems that it should be so. The following sentence might be uttered if the speaker had just returned from out of town, and been asked if they'd done something, or heard something, that implied more time at home than they had yet had:
ni-ku-lai he-ele i mono
1SG-KNOWN-return TIME-yesterday FIN only
"I mean, I only came back yesterday, after all"
As an interjection, then, ku means something like "obviously," "clearly" or "of course," and the negative form kuná would be "obviously not," "of course not," "clearly not."
For those particles that do not have veridical or evidential force -- that is, other than ia, li, pu, vu -- the positive form can also be combined with ia for emphasis, thus kuiá "clearly yes," "well of course it is." All of these particles are modular and can be combined freely in whatever ways their meanings would allow: so iaté "yes, that very well may be," "it is definitely true that that is possible" vs teiá "yes, perhaps," "it's possible that that's true." Or even stacked with other modals, like kuté, kuteiá "yes, that may indeed be possible."
Below are the particles that can be used as interjections and their approximate English meanings. One note for the following examples: "I" in the translations is only illustrative, and could be replaced with any other referent relevant to the discourse (e.g. oená could also mean "no, she shouldn't" in the appropriate context).
ea "yes, let's"
eaná "no, let's not"
hoiá "yes, actually, counter to expectations" (ho alone indicates surprise)
honá "no, actually not, counter to expectations"
ia "yes, definitely"
ianá "no, definitely not"
io "that's right, there it is, aha!, bingo, there we go"
ioná "no, no way, no longer, no more of that"
ki "yes, I have to; yes, it must be"
kiná "no, I mustn't; no, it must not be"
nakí "no, I don't have to; no, there's no need"
ku "yes, obviously; yes, of course"
kuná "no, obviously not, of course not"
li "yes, I suppose so, might be, probably"
liná "no, I suppose not, probably not"
lu "yes, I want to"
luná "no, count me out"
nalú "no, I don't want to"
oe "yes, I should"
oená "no, I shouldn't"
pu "yes, apparently; yes, so I hear"
puná "no, apparently not; no, so I hear"
te "yes, I can; yes, maybe"
tená "no, maybe not"
naté "no, I can't; no, it can't be"
vi "yes, do it! yes, let it be so!"
navi, naví "no, don't do it! ojalá que no"
vu "yeah, I guess so"
vuná "no, I guess not"
I'm really pretty pleased with the amount of subtlety and precision that Koa has developed in this area sort of by accident, just by virtue of its system of modal particles. I know I keep saying this but it's been continually fascinating to keep discovering the language's emergent complexity as it's come into greater and greater use this year.
Thursday, March 16, 2023
Word break conventions and emergent typology
I've been doing a lot of free-form writing in Koa this year and it's been a pretty revealing experience. There's nothing that exposes semantic gaps and structural shortcomings like trying to write complex, expressive prose; initially all my writing felt unbelievably clumsy, with none of the grace, sophistication or subtlety that I try to embody when I write in other languages I know well. After a month or two, though, I feel like I'm starting to find my voice in Koa -- or maybe more accurately, Koa is finding its own nascent voice.
This is really the first constructed language in which I've navigated this process and it's fascinating (and intimidating): coming from a place of only having written single, unconnected example sentences, how does the language in question construct, say, a whole paragraph? How does it flow structurally? I feel so practiced in other areas of language design, but here I'm just doing my best to move through it all in an intuitive way without getting hung up on my own anxiety. Someday I'll have to try to actually articulate some of these emergent principles, but I think they need time to emerge further first.
In the mean time, another thing that came up as I began keeping a regular journal in Koa was a discovery I only made when I tried to read what I'd written later on. For one thing, I knew theoretically that production and comprehension were different disciplines, but I wasn't quite prepared for just how unpracticed I was at understanding my own language. It makes sense: I'd really never had the opportunity to try to interpret speech or writing coming at me before! In response I added a word recognition module to my vocab learning program; previously it had only been testing me on production in the target language.
More surprisingly, though, it turned out that the way I've always represented Koa is kind of hard to parse. Here's an example block of text written in the traditional style:
Ta lai la ka ásulo ta la ko vúakupu e ko mivami, sii, ta mene la ko kóuva e tule lai la ni. Ni si vima poli lo kopato ve hua i cu misucu, ala he lopu poka i pea pono e ka lila ni sai i si kali. E ka tana i kali i koe ka sena. Hala kehe nu lu nike la ko mova ka kecu, ka nu lu ete la ko mupea ka háote nu ne kene koa.
As soon as I start to read it my eyes sort of go out of focus; with such a rapid stream of little words it's hard for me to keep track of where I am in the text, let alone where I am in the syntactic tree. As a result, over the past month I've been experimenting with writing roots with their particles attached to them. The precise rules about what should be attached and what should be left separate are still developing, but the essence of the system has come together nicely. Here's what that previous paragraph looks like with the new conventions:
Talai lakaásulota lakovúakupu e komivami, sii, tamene lakokóuva e tule lai laní. Nisivima poli lokopato ve hua i cumisucu, ala helopu poka i pea pono e kalílani sai i sikali. E katana i kali i koe kasena. Hala kehe nulunike lakomova kakecu, kanuluete lakomupea kaháotenu nekene koa.
Even though this was unfamiliar, I instantly found it massively easier to parse. Allison said that made sense to the extent that there were many more word shapes now for the brain to grab onto; it's also entirely clear which particles belong to which roots, and morpheme clusters mirror natural intonation groups. Here's an attempt to articulate the principles of the system.
1. Particles whose scope is a predicate -- regardless of how complex it is is -- are written together with that predicate. This may require the use of additional accentuation where possessive pronouns and directionals are suffixed to the root.
ninasitemuláheta = "I couldn't make him leave"
2. Particles whose scope is a clause with a pronominal subject are joined joined to that clause (but see point 6)
nisánota lakomutulu kakúmumani = "I said it to make my teacher angry"
3. Particles whose scope is a clause with a full subject NP are separated from surrounding words
nitovo ko le Kéoni i cutule = "I hope that John will come"
4. Predicate clusters -- compounds and incorporated objects -- are written together, but plain adjectival phrases are not joined to their head nouns
kalopuviko = "the weekend," but
kapasano vime = "the last statement"
5. Pronominal particles follow the same rules as predicates when used as the head of an NP, but must be marked with an accent.
laní = to me
nahunú = none of us
6. Certain particles, principally with clause-level scope, are always written separately: i, e when it means "and," au, ai, ha when it means "if," ve when used as a complementizer, and ko when used alone as a complementizer (this list may not be exhaustive). Le is also separated from its head to avoid muddlement with capitalization and foreign words.
One point of uncertainty: when a particle is written separately from its head but is itself within the scope of other particles, are those particles also separated or should they be attached to the "frontmost" one? For example, which of the following should be the convention?
nisánota lako le Kéoni i cutule
nisánota la ko le Kéoni i cutule
"I said it so that John would come"
A bunch of this, incidentally, may actually be an artifact of trying to smoosh Koa into an alphabetic writing system. If the language could be written with a syllabary rather than an alphabet, and if there were some marking that identified the stressed syllable of predicates -- in other words, if predicates were instantly differentiated visually from particles -- then there would be a much closer match between writing and Koa's native structure.
But what, then, is Koa's native structure? I had always thought of it as a basically isolating language, but one thing that really surprised me when I first saw text written with these new conventions is how...agglutinating it looks. I'm sort of shocked that I've never asked this question before, but...where does the structure of Koa really fit, typologically?
The language is certainly about as close as you can get to monoexponential in that each morpheme is (theoretically) encoding one and only one semantic, and since I've been thinking of all particles and predicates as individual "words," my unconsidered classification of isolating seemed justified. But looking at forms like this one from above...
ni-na-si-te-mu-láhe-ta
1SG-NEG-ANT-ABIL-CAUS-leave-3SG
"I couldn't make him leave"
...I really wonder on what grounds I would not call that a "word." A word constituting a complete sentence, with seven morphemes, which a Turkish speaker could feel right at home with. And if that resemblance isn't just incidental but in fact diagnostic, then classifying those first five morphemes as "particles" is obscuring something important: they're actually prefixes. Occupying slots, in a specific order. Like an agglutinative language.
I'm actually not sure how to make a ruling on this, and more thought and research may be required. Some of those particles certainly can stand on their own in certain contexts -- nate "no, I can't," or keka sa? ni "who is it? me" -- and maybe more revealingly, the pronouns can appear to be gapped:
ka-Ø-na-si-te-mu-láhe-ta
DEFᵢ-Øᵢ-NEG-ANT-ABIL-CAUS-leave-3SG
"the one who couldn't make him leave"
ka-ni-na-si-te-mu-lahe-Ø
DEFᵢ-1SG-NEG-ANT-ABIL-CAUS-leave-Øᵢ
"the one I couldn't make leave"
On the other hand I've vigorously maintained previously that gapping is in fact not the best explanation for these structures despite the fact that it's possible to draw the trees that way. It may be that this new word break convention and the kinds of apparent agglutinative "words" it produces is itself also obscuring some of the true nature of the base structures. Ultimately this is not a question of graphical representation -- whether we write ni na si te mu lahe ta or ninasitemuláheta -- but what's really happening below the surface. And I'm starting to tie my brain in knots which is a pretty clear sign that I need to put down this problem for a bit.
More to come, clearly.
Tuesday, March 7, 2023
A parting of the ways
My decision last month to remove all predicate roots beginning with /j/ from the Koa lexicon sparked a significant artistic crisis. I tried to accept the replacements, but as time passed I was confronted with a growing feeling that this change was not okay. I loved those proscribed roots, loved the variation in syllable structure that they provided, and realized that I would like Koa less without them; worse than that, that it would feel like it had lost some of the essence of itself. It would feel like it was no longer mine.
I was clearly right when I said that this phoneme had no place given Koa's charter, but it just doesn't matter: apparently at this point the language has developed such a strong sense of itself, especially after all the vocabulary creation and writing that's been going on this year, that honoring that personality is actually more important. The charter was supposed to be an inspiration, not a prison, and the fact is that I love what Koa has become so much that I would rather change the limits than stifle the language to fit within them.
This may seem like a lot of fuss over 20 roots and a marginal phoneme, but this is the first time I've ever consciously and intentionally prioritized aesthetics over the language's ease or clarity. It's uncomfortable, but also unquestionably the right decision.
Emboldened by this I've found myself thinking crazy thoughts, like considering adding another consonant phoneme. I experimented with [ŋ] and was shocked to discover that I actually loved it, and that it "felt" like Koa despite the fact that it would be completely off the deep end charter-wise. I don't know that I'll really go down that path, but it's sort of a wonderful thing that after 23 years there is something that Koa "feels like" to such a clear extent that it can begin to direct its own course into territory I'd never imagined.
Over the weekend I reinstated all my exiled vocabulary. It was a tremendous relief. Honestly I think I would have died on that hill for iolo alone.
Saturday, February 18, 2023
Lament for the vanished on-glides
Although /j/ as a formal phoneme had been officially nixed a few years previous, beginning in 2011 a number of words appeared in Koa with an initial [j] sound: iolo "joyful," iuna "train," iune "steal," and so on. This was possible because of the adoption of a series with this sound among the particles: ia "yes, definitely," io "already," etc., for which I could think of no objection.
As of this morning the language contained around 20 predicates with this on-glide. I still think the particles are fine, but it suddenly crystallized for me that there was a serious problem with the predicates: the accidental adoption of this phoneme created a growing functional load on the distinction between prevocalic [j], [i] and [ij]:
ka kane iolo
[ka kane jolo]
"the joyful man"
ka kane i olo
[ka kane i olo]
"the man smells (something)"
ka kane i iolo
[ka kane i jolo]
"the man is joyful"
As I've been experimenting with writing Koa without spaces between bound morphemes (post eventually forthcoming) the problem became very stark: the phrases above come out kakane iolo, kakane iolo, and kakane iiolo! It's even worse when the preceding predicate also ends with /i/:
ka hapi iolo
[ka hapi jolo]
"the joyful ant"
ka hapi i olo
[ka hapi i olo]
"the ant smells (something)"
ka hapi i iolo
[ka hapi i jolo]
"the ant is joyful"
...so here we're making a distinction between [ijo], [iio] and [iijo]. Heavens above. As much as it -- truly, sincerely, kind of agonizingly -- grieves me, these just couldn't stand: in an artlang, sure, but not with Koa's charter. They just weren't meant to be.
And so, glumly, this afternoon I went through and reassigned all of these predicates. Some of them feel okay, others may take some getting used to or find themselves replaced eventually. The hardest one by far was iolo: there is just no other sequence of sounds that more clearly communicates joy to me after having it as a core predicate for more than ten years. I feel like I want to keep it around as an archaic alternative usable in poetry.
Anyway, for posterity, here are the lost on-glide roots; farewell, and I'll remember you always.
iaho -> auho "flour"
iali -> ali "put away"
iane -> ane "cord"
iapu -> epu "spit"
iehi -> ehi "hate"
iela -> sela "whole, unbroken"
ietu -> cetu "dishonor"
ieva -> teva "gradual"
ioco -> oco "copper"
iolo -> elo "joyful"
iomu -> omu "meat"
ioni -> coni "yoni"
ioti -> toti "perseverate"
iotu -> enu "curious"
iovi -> kovi "wise"
iule -> ulu "apart"
iuna -> vona "train"
iune -> lune "steal"
iuve -> uve "fall short"
Ooh, some of these are still not feeling great...I can tell I'm going to have to give myself time.
Thursday, February 2, 2023
Consonant use statistics
This morning I focused for the first time on the fact that my little random word program -- the database that suggests Koa roots in need of meanings -- is suggesting roots containing /c/ a disproportionate amount of the time. This in itself wasn't surprising: /c/ only returned to active use about 15 months ago, so it would make sense that more roots containing it would be available. It made me wonder, though, just how much variation there is in consonant phoneme frequency in Koa. I ran some numbers...
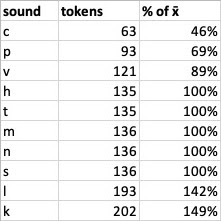
On the other end of things, /k/ and /l/ are significantly overrepresented at nearly 150% of average! ...Which also kind of makes sense because they're also favorites of mine.
I guess it just hadn't occurred to me that my own personal aesthetics would have figured so prominently in root choice with respect to phoneme frequency! I must have expected that each consonant would appear approximately equally, as odd as that would have been cross-linguistically?
That raises a really interesting point, though, which I also had never considered: the particular character of Koa as it has always existed manifests these frequency biases. Like any language, the phonemes are represented unequally, and that gives it an important part of its unique phonological character. As such, moving towards greater uniformity -- as my random picker would automatically tend to do -- would, over time, actually alter the feel of Koa.
And if I like the phonological aesthetics as they've been up to this point -- which it turns out I do -- I may actually not want to continue generating words this way! I'm not sure yet exactly how I'll do this, but what we really want is for the randomness to be weighted -- towards words with Koa's favorite phonemes, and away from words with those it prefers less -- such that a random sample of suggested words would tend to show the same frequency distribution as the language as a whole.
I almost wonder if I should go back to an earlier version of the file, run these numbers again, and use those statistics; the program potentially had a noticeable impact on the frequencies with those 200+ words in the past couple months. Though...on the other hand I was still vetting the choices so my aesthetics were still probably in force, even if being nudged. I could figure out the statistics of the recent additions on their own just to be sure.
Anyway this is certainly an interesting little surprise for me to ponder.
Sunday, January 29, 2023
Etymology statistics
Just a point of interest as I continue to organize my lexicon...
Of the 790 predicate roots assigned so far:
* 163 (21%) are derived from Finnish
* 57 (7%) are derived from Hawai'ian, Sāmoan, Tongan or Māori
* 75 (9%) are derived from other languages (Arabic, Basque, Bislama, Chinese, Doraja, Esperanto, French, Greek, Icelandic, Irish, Japanese, Latin, Lapine, Latvian, Malay, Nahuatl, Polish, Proto-World [ha ha], Quechua, Quenya, Russian, Seadi, Spanish, Swahili, Tagalog, Turkish, Swahili, or broad international usage)
* 34 (4%) are internally-derived
This means 295 (37%) of the current Koa root stock was derived in some way from other languages, compared with 495 (63%) that was either randomly generated, internally derived, or selected/created in some way (unfortunately there's no good way to distinguish randomness from intention reliably at this point). I find these figures a little surprising: it was my impression that the significant majority of Koa words was based in something -- to the point that I was stymied for a long time in creating more vocabulary when I couldn't find enough existing linguistic inspiration. Also, again, let's just pause for a second to acknowledge that Finnish has provided a fifth of Koa vocabulary.
Worthy of special mention are 6 roots (1%) that were created by friends or family members -- I'd love to swell that number moving forward!