Although /j/ as a formal phoneme had been officially nixed a few years previous, beginning in 2011 a number of words appeared in Koa with an initial [j] sound: iolo "joyful," iuna "train," iune "steal," and so on. This was possible because of the adoption of a series with this sound among the particles: ia "yes, definitely," io "already," etc., for which I could think of no objection.
As of this morning the language contained around 20 predicates with this on-glide. I still think the particles are fine, but it suddenly crystallized for me that there was a serious problem with the predicates: the accidental adoption of this phoneme created a growing functional load on the distinction between prevocalic [j], [i] and [ij]:
ka kane iolo
[ka kane jolo]
"the joyful man"
ka kane i olo
[ka kane i olo]
"the man smells (something)"
ka kane i iolo
[ka kane i jolo]
"the man is joyful"
As I've been experimenting with writing Koa without spaces between bound morphemes (post eventually forthcoming) the problem became very stark: the phrases above come out kakane iolo, kakane iolo, and kakane iiolo! It's even worse when the preceding predicate also ends with /i/:
ka hapi iolo
[ka hapi jolo]
"the joyful ant"
ka hapi i olo
[ka hapi i olo]
"the ant smells (something)"
ka hapi i iolo
[ka hapi i jolo]
"the ant is joyful"
...so here we're making a distinction between [ijo], [iio] and [iijo]. Heavens above. As much as it -- truly, sincerely, kind of agonizingly -- grieves me, these just couldn't stand: in an artlang, sure, but not with Koa's charter. They just weren't meant to be.
And so, glumly, this afternoon I went through and reassigned all of these predicates. Some of them feel okay, others may take some getting used to or find themselves replaced eventually. The hardest one by far was iolo: there is just no other sequence of sounds that more clearly communicates joy to me after having it as a core predicate for more than ten years. I feel like I want to keep it around as an archaic alternative usable in poetry.
Anyway, for posterity, here are the lost on-glide roots; farewell, and I'll remember you always.
iaho -> auho "flour"
iali -> ali "put away"
iane -> ane "cord"
iapu -> epu "spit"
iehi -> ehi "hate"
iela -> sela "whole, unbroken"
ietu -> cetu "dishonor"
ieva -> teva "gradual"
ioco -> oco "copper"
iolo -> elo "joyful"
iomu -> omu "meat"
ioni -> coni "yoni"
ioti -> toti "perseverate"
iotu -> enu "curious"
iovi -> kovi "wise"
iule -> ulu "apart"
iuna -> vona "train"
iune -> lune "steal"
iuve -> uve "fall short"
Ooh, some of these are still not feeling great...I can tell I'm going to have to give myself time.
Saturday, February 18, 2023
Lament for the vanished on-glides
Thursday, February 2, 2023
Consonant use statistics
This morning I focused for the first time on the fact that my little random word program -- the database that suggests Koa roots in need of meanings -- is suggesting roots containing /c/ a disproportionate amount of the time. This in itself wasn't surprising: /c/ only returned to active use about 15 months ago, so it would make sense that more roots containing it would be available. It made me wonder, though, just how much variation there is in consonant phoneme frequency in Koa. I ran some numbers...
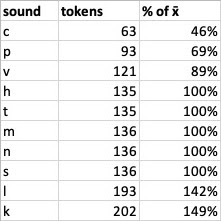
On the other end of things, /k/ and /l/ are significantly overrepresented at nearly 150% of average! ...Which also kind of makes sense because they're also favorites of mine.
I guess it just hadn't occurred to me that my own personal aesthetics would have figured so prominently in root choice with respect to phoneme frequency! I must have expected that each consonant would appear approximately equally, as odd as that would have been cross-linguistically?
That raises a really interesting point, though, which I also had never considered: the particular character of Koa as it has always existed manifests these frequency biases. Like any language, the phonemes are represented unequally, and that gives it an important part of its unique phonological character. As such, moving towards greater uniformity -- as my random picker would automatically tend to do -- would, over time, actually alter the feel of Koa.
And if I like the phonological aesthetics as they've been up to this point -- which it turns out I do -- I may actually not want to continue generating words this way! I'm not sure yet exactly how I'll do this, but what we really want is for the randomness to be weighted -- towards words with Koa's favorite phonemes, and away from words with those it prefers less -- such that a random sample of suggested words would tend to show the same frequency distribution as the language as a whole.
I almost wonder if I should go back to an earlier version of the file, run these numbers again, and use those statistics; the program potentially had a noticeable impact on the frequencies with those 200+ words in the past couple months. Though...on the other hand I was still vetting the choices so my aesthetics were still probably in force, even if being nudged. I could figure out the statistics of the recent additions on their own just to be sure.
Anyway this is certainly an interesting little surprise for me to ponder.
Subscribe to:
Posts (Atom)